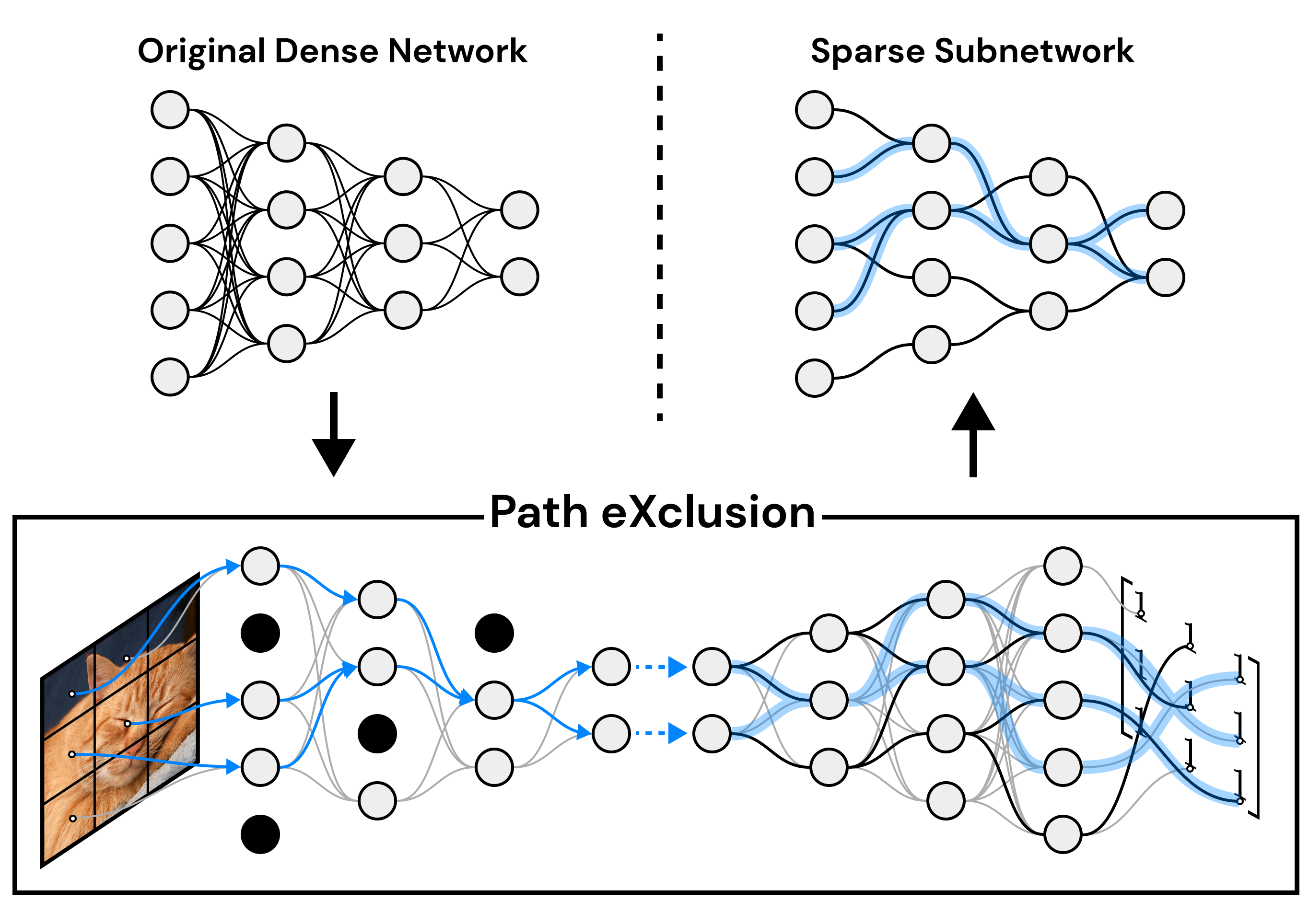
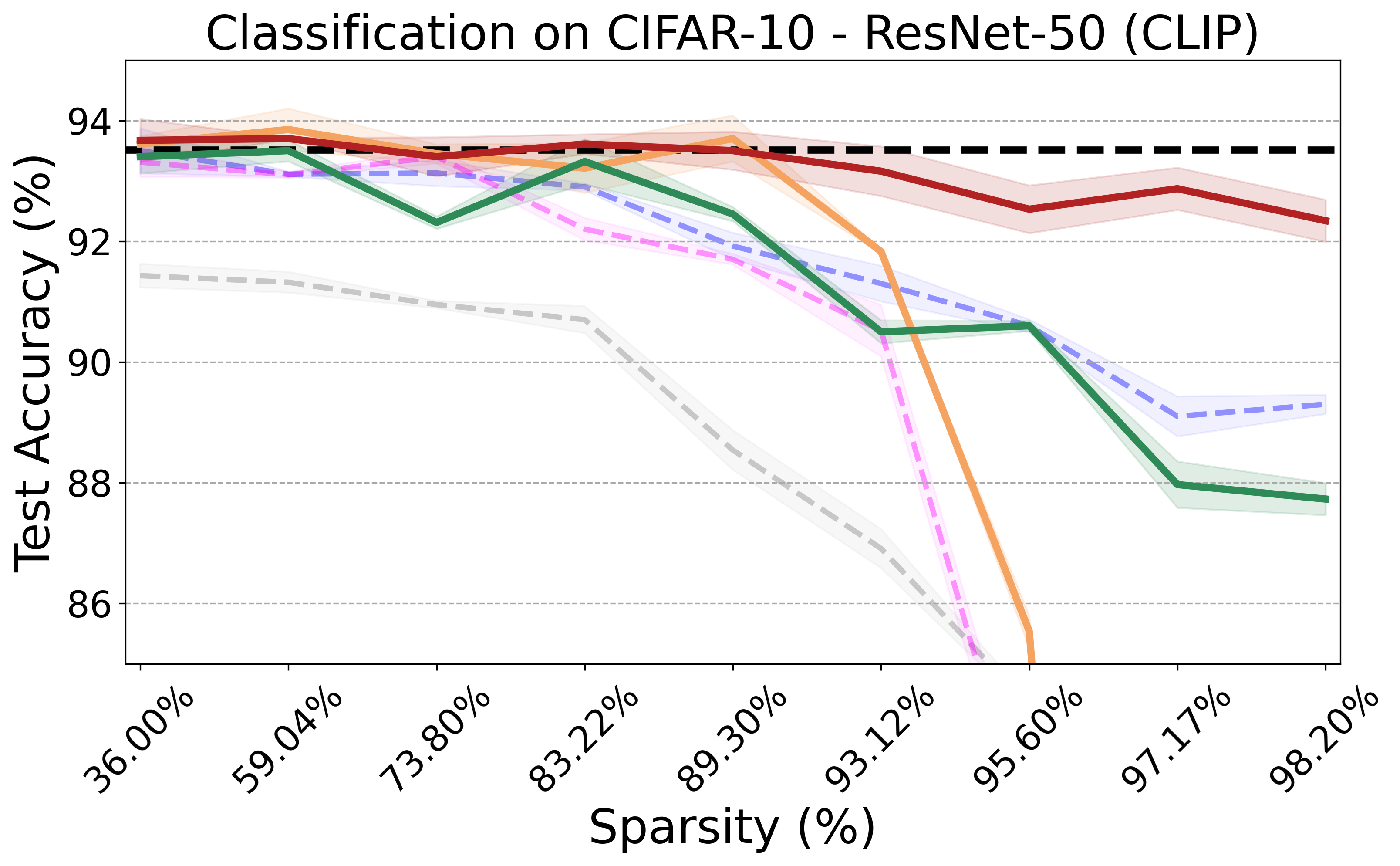
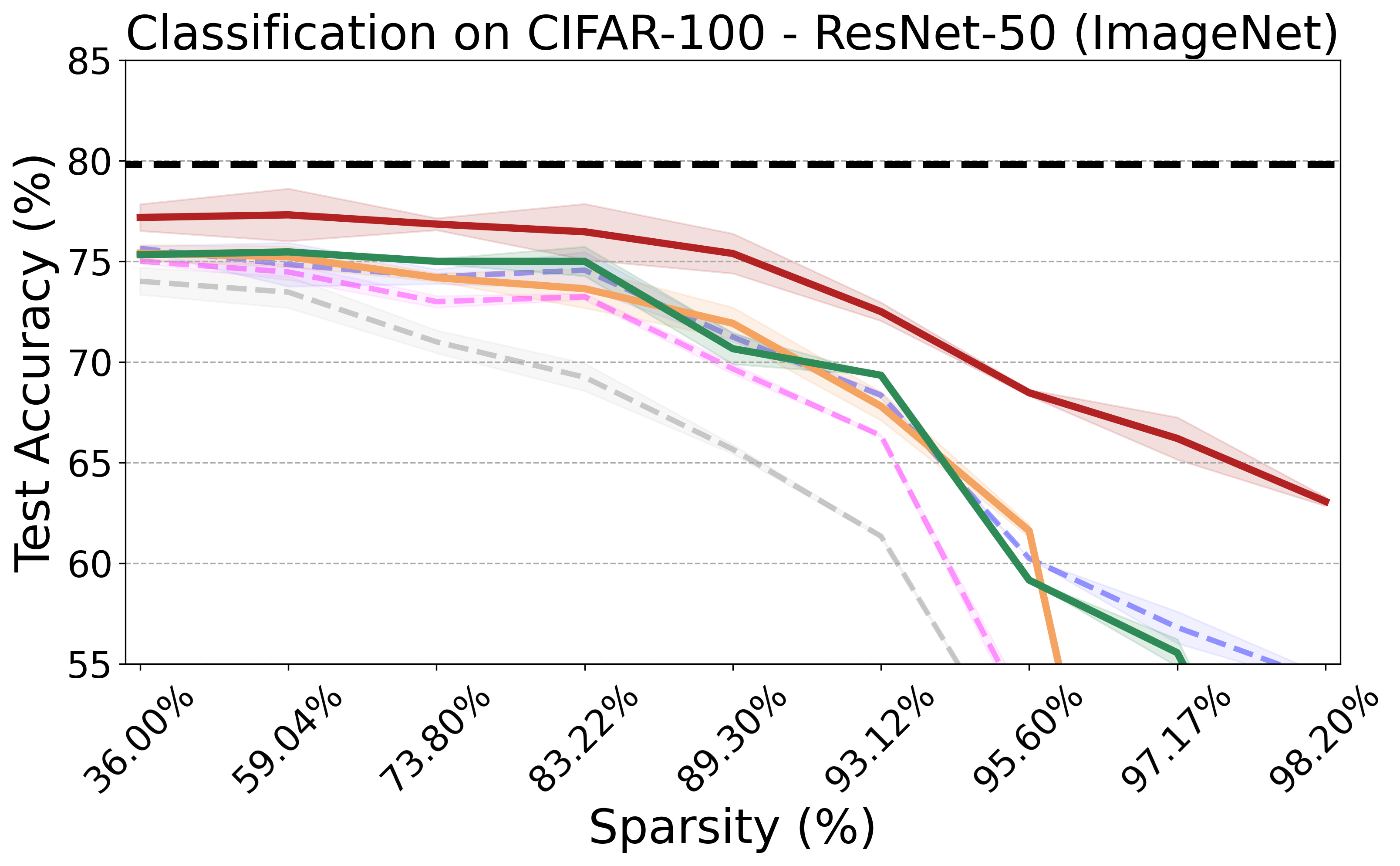
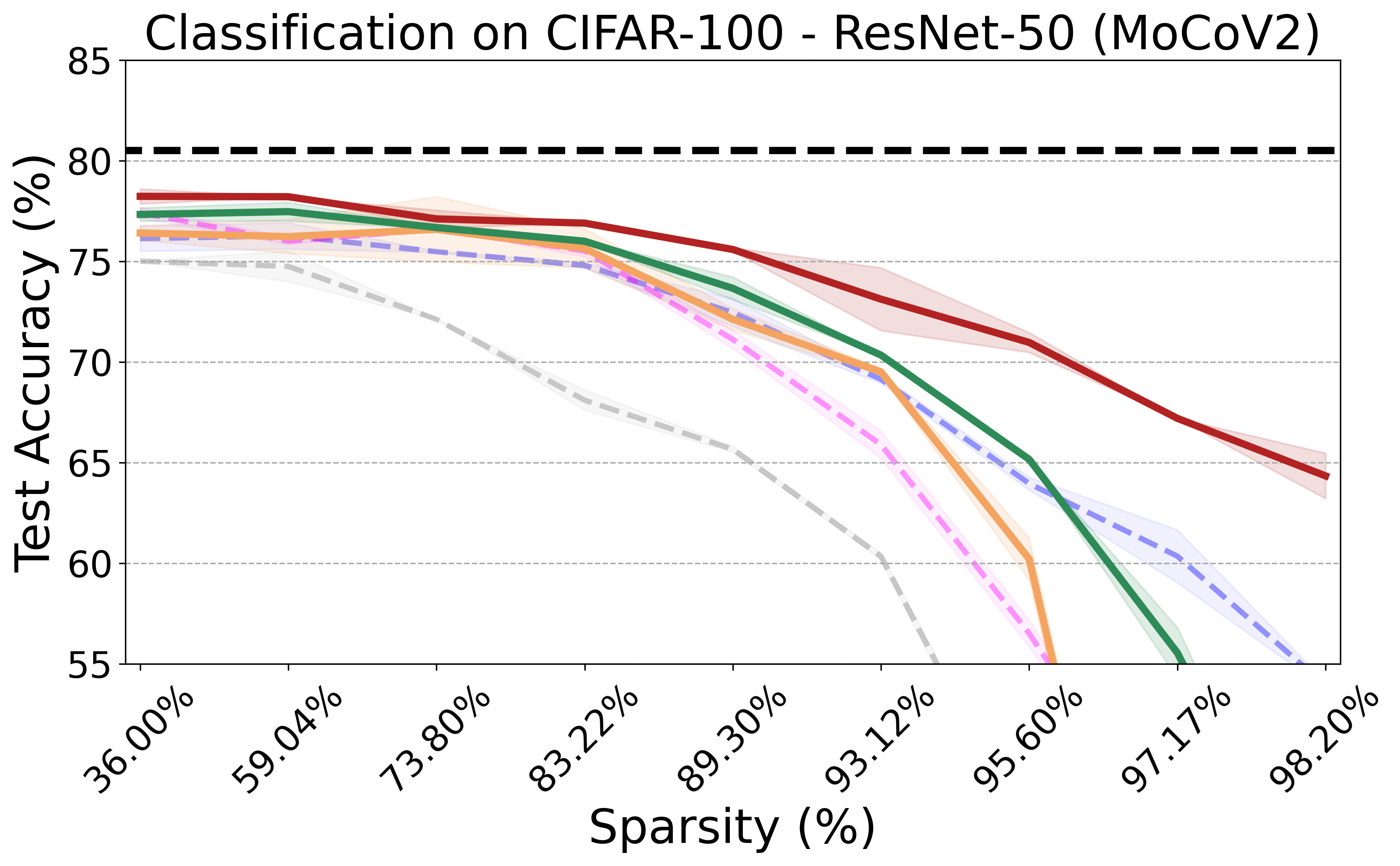
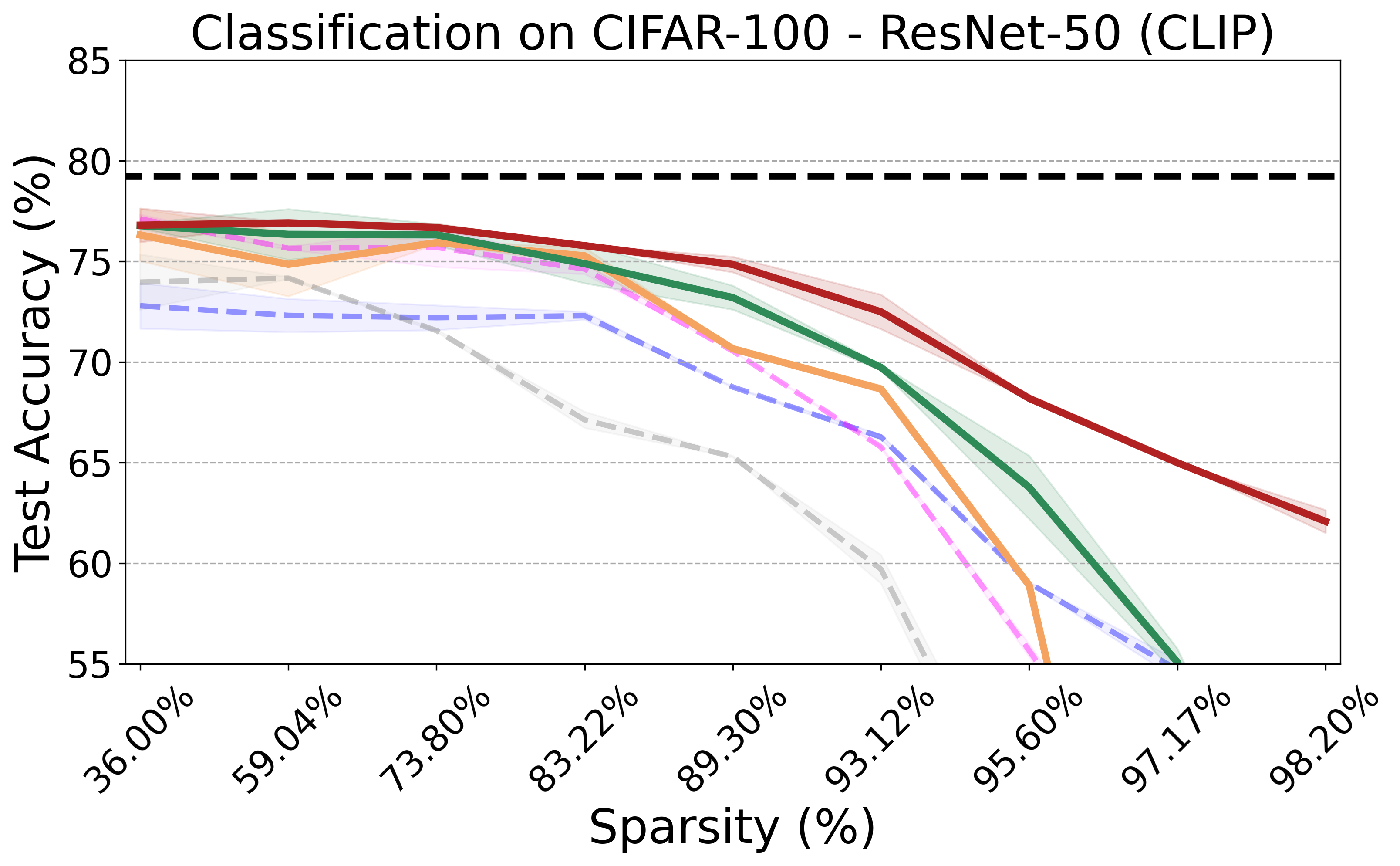
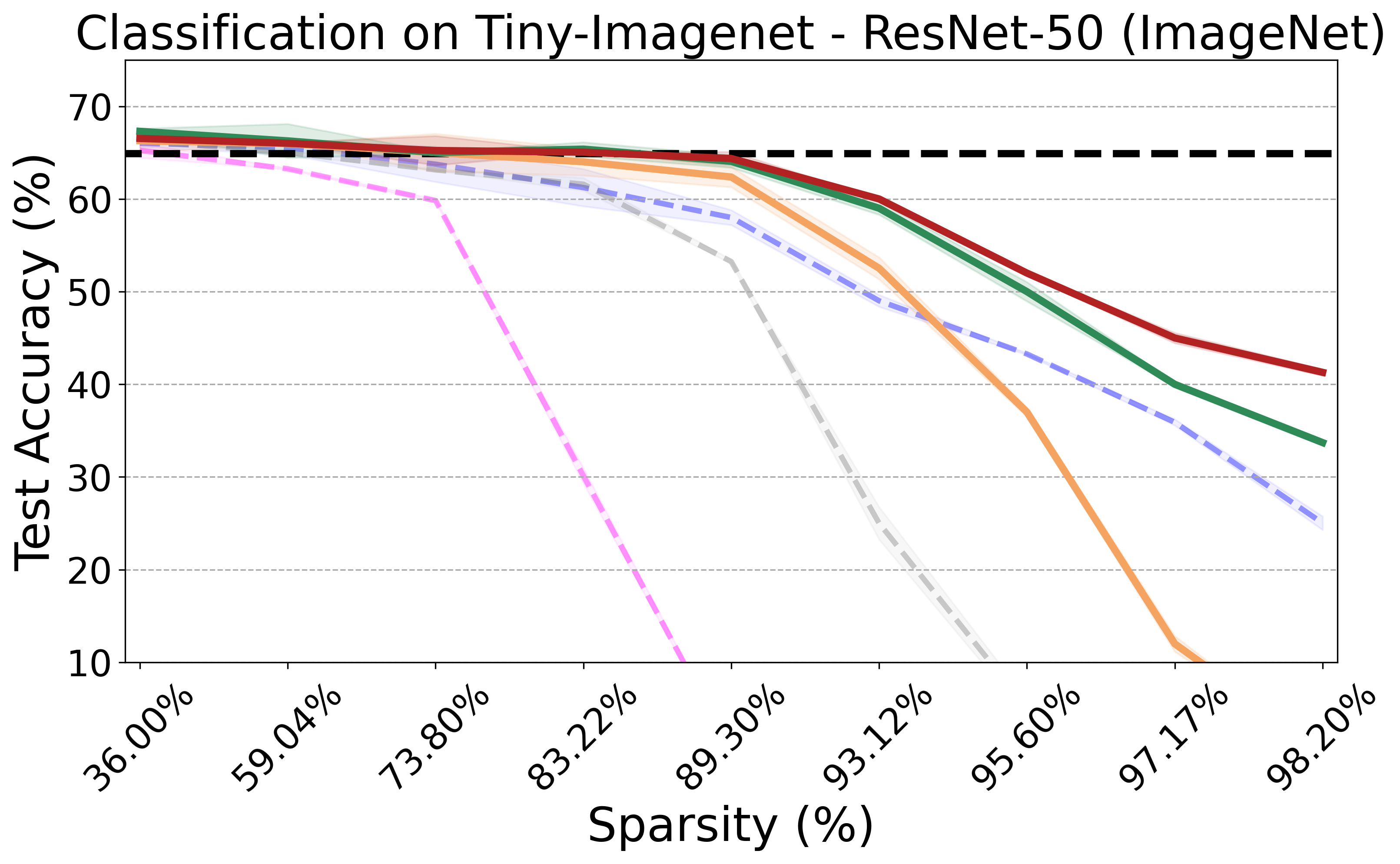
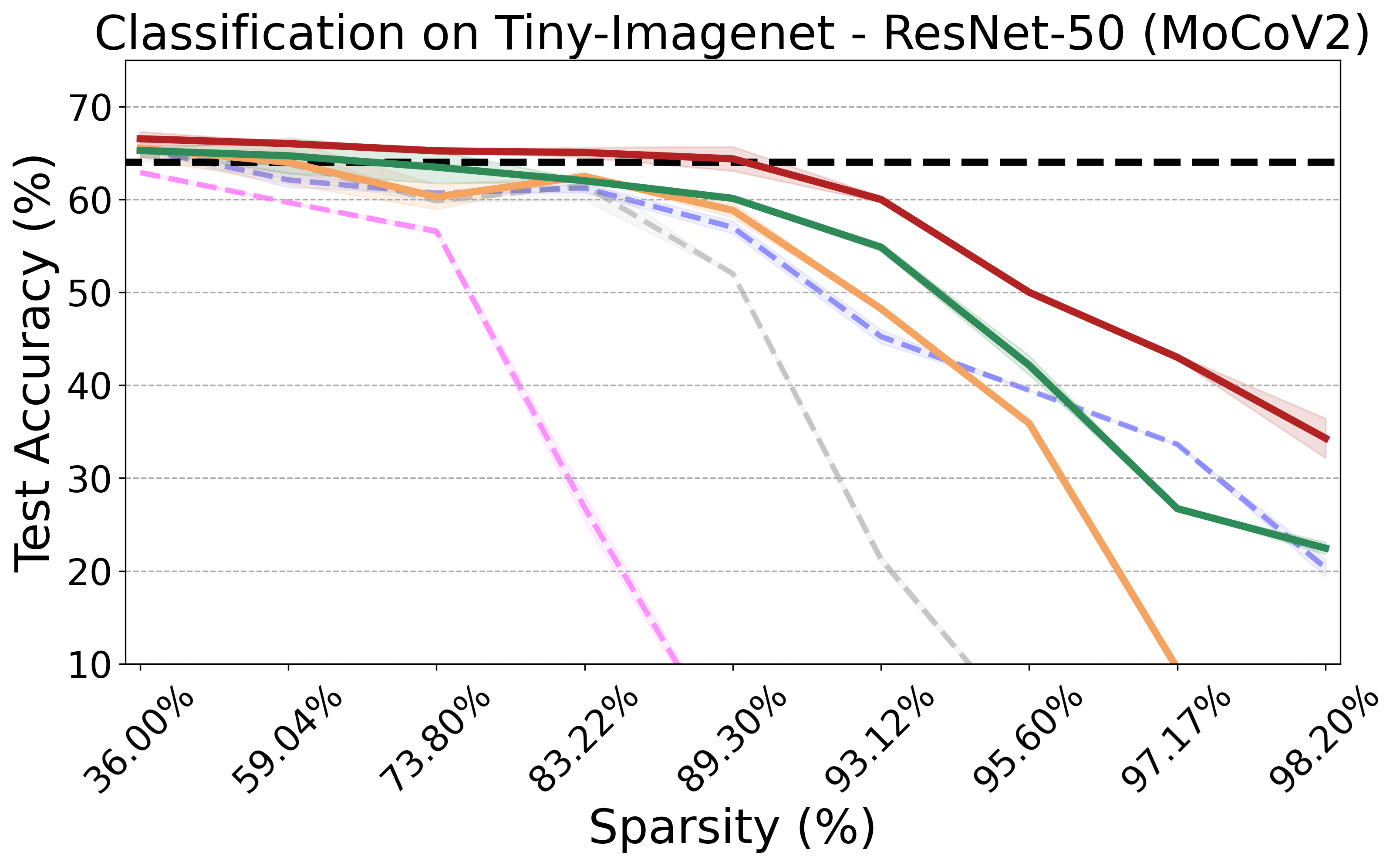
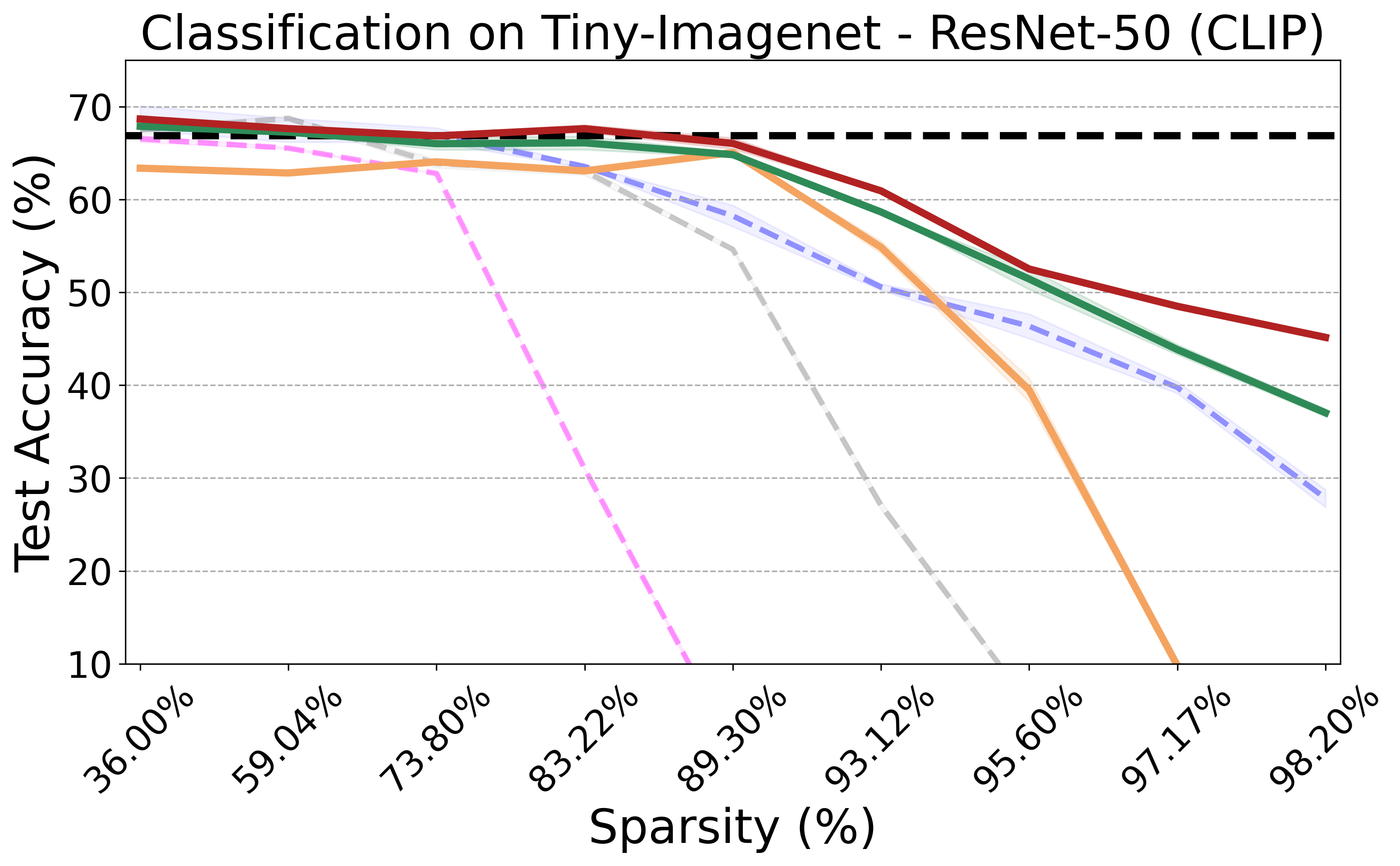
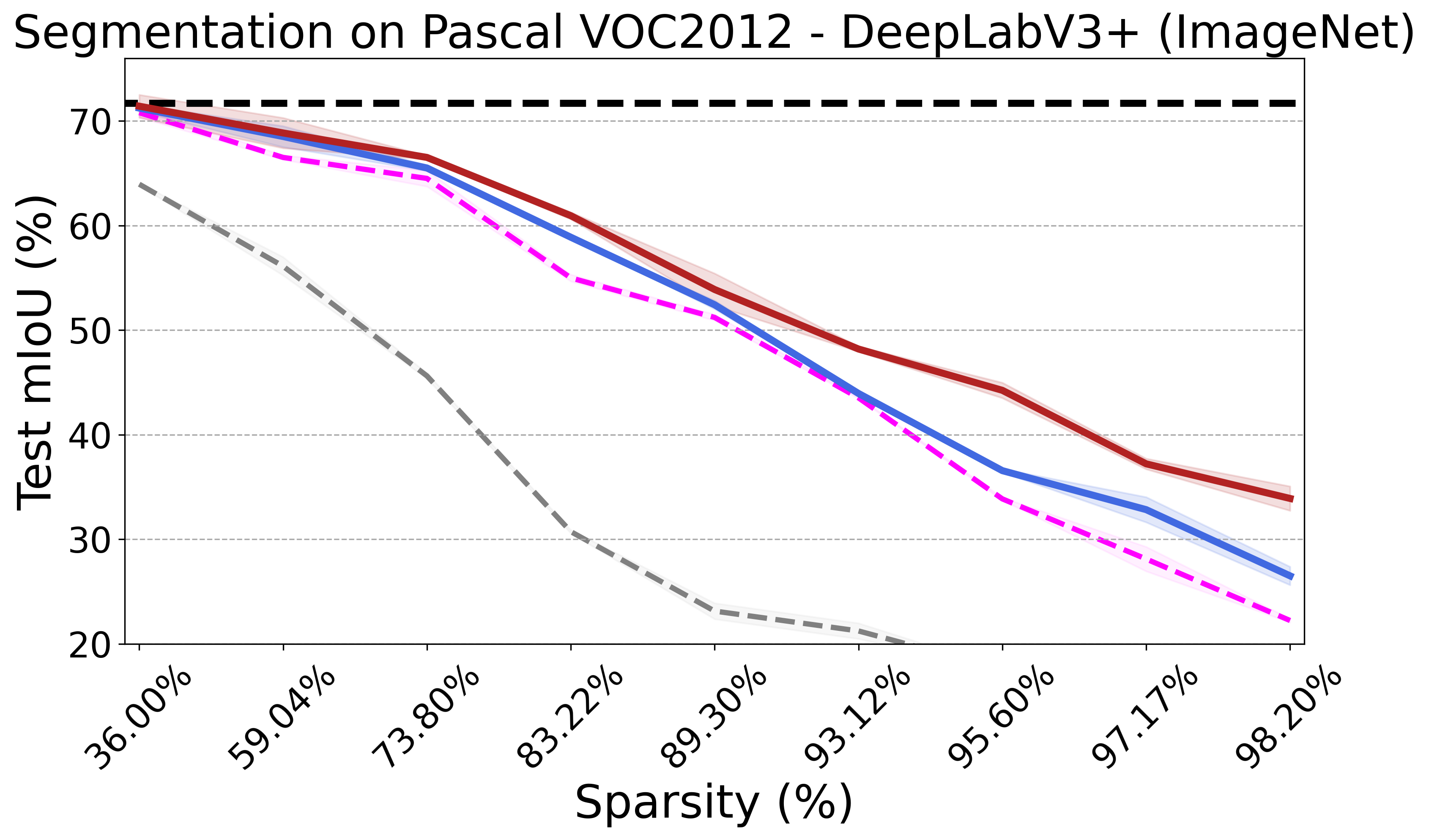
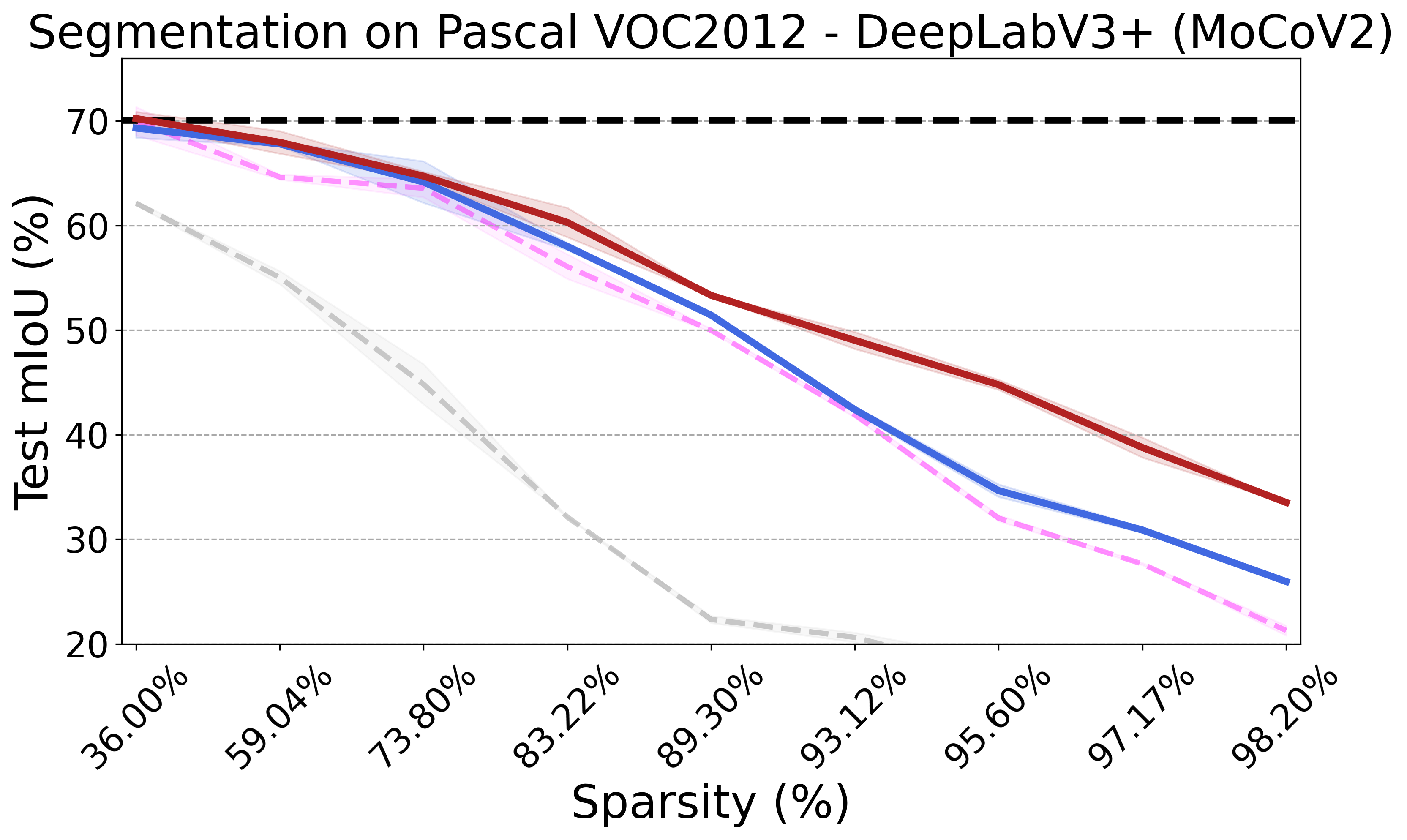
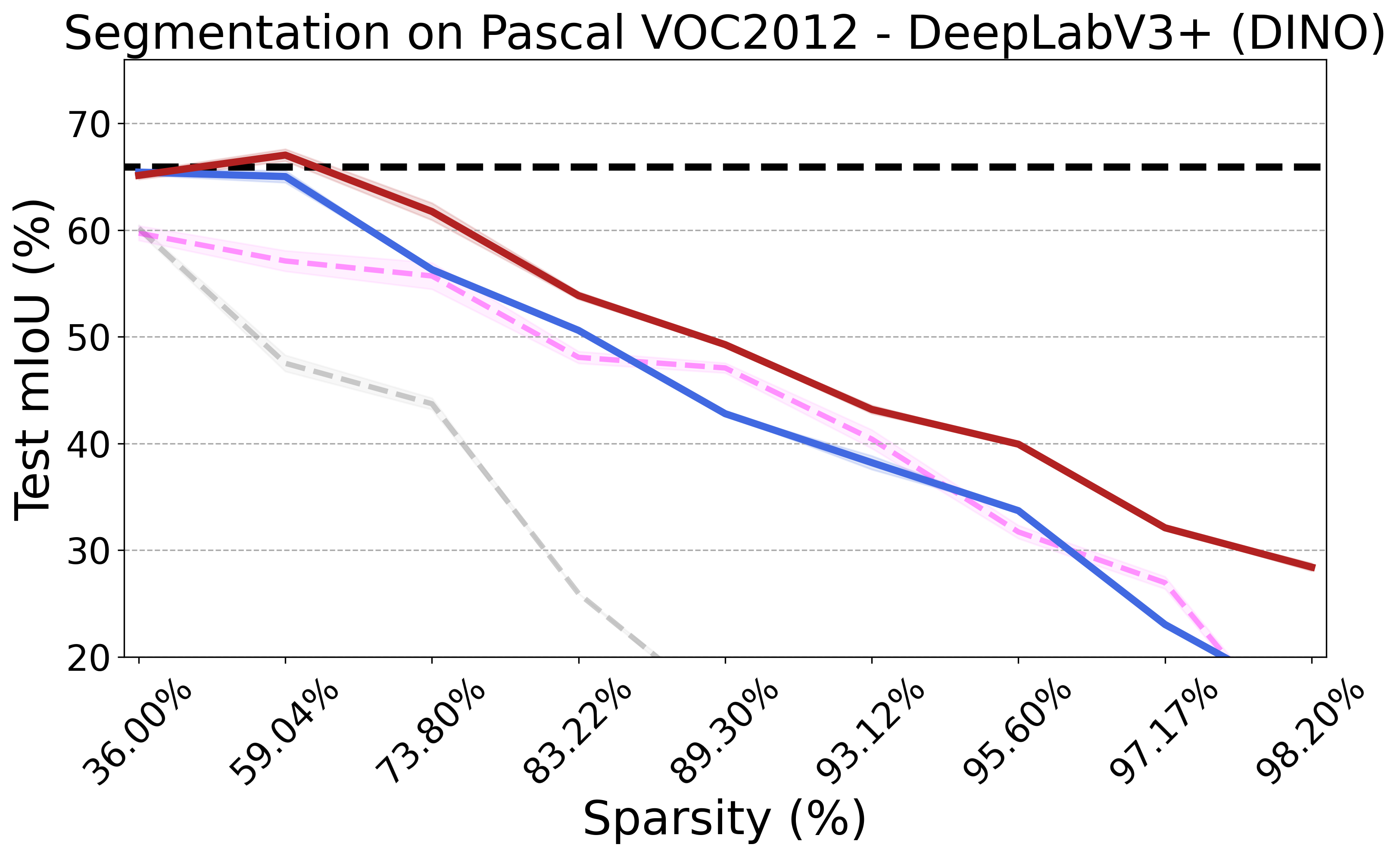
Recent advances in neural network pruning have shown how it is possible to reduce the computational costs and memory demands of deep learning models before training. We focus on this framework and propose a new pruning at initialization algorithm that leverages the Neural Tangent Kernel (NTK) theory to align the training dynamics of the sparse network with that of the dense one. Specifically, we show how the usually neglected data-dependent component in the NTK's spectrum can be taken into account by providing an analytical upper bound to the NTK's trace obtained by decomposing neural networks into individual paths. This leads to our Path eXclusion (PX), a foresight pruning method designed to preserve the parameters that mostly influence the NTK's trace. PX is able to find lottery tickets (i.e. good paths) even at high sparsity levels and largely reduces the need for additional training. When applied to pre-trained models it extracts subnetworks directly usable for several downstream tasks, resulting in performance comparable to those of the dense counterpart but with substantial cost and computational savings.
Our paper introduces a novel pruning algorithm, Path eXclusion (PX), designed to enhance the efficiency of neural networks by pruning at initialization. Leveraging Neural Tangent Kernel (NTK) theory, PX focuses on identifying and retaining the most critical network paths, ensuring minimal performance loss even when the network is transferred to new tasks.
The PX algorithm iteratively prunes network weights that have minimal impact on the NTK trace, thus preserving essential paths and maintaining the training dynamics of the resulting subnetwork aligned with its dense counterpart. Improving on current pruning methods focusing on the NTK theory, our approach leverages a new upper bound for the NTK trace, which takes into account the network's input-output paths based on architecture and weight values (captured by the Path Kernel \(J_\theta^v\)) and how data maps onto such paths (captured by the Path Activation Matrix \(J_v^f(X)\)). Formally, our upper bound is defined as \[\text{Tr}[\Theta(X,X)] = \|\nabla_\theta f(X,\theta)\|_F^2 = \|J_v^f(X) J_\theta^v \|_F^2 \leq \|J_v^f(X)\|_F^2 \cdot \|J_\theta^v \|_F^2, \] which can be efficiently computed using automatic differentiation.
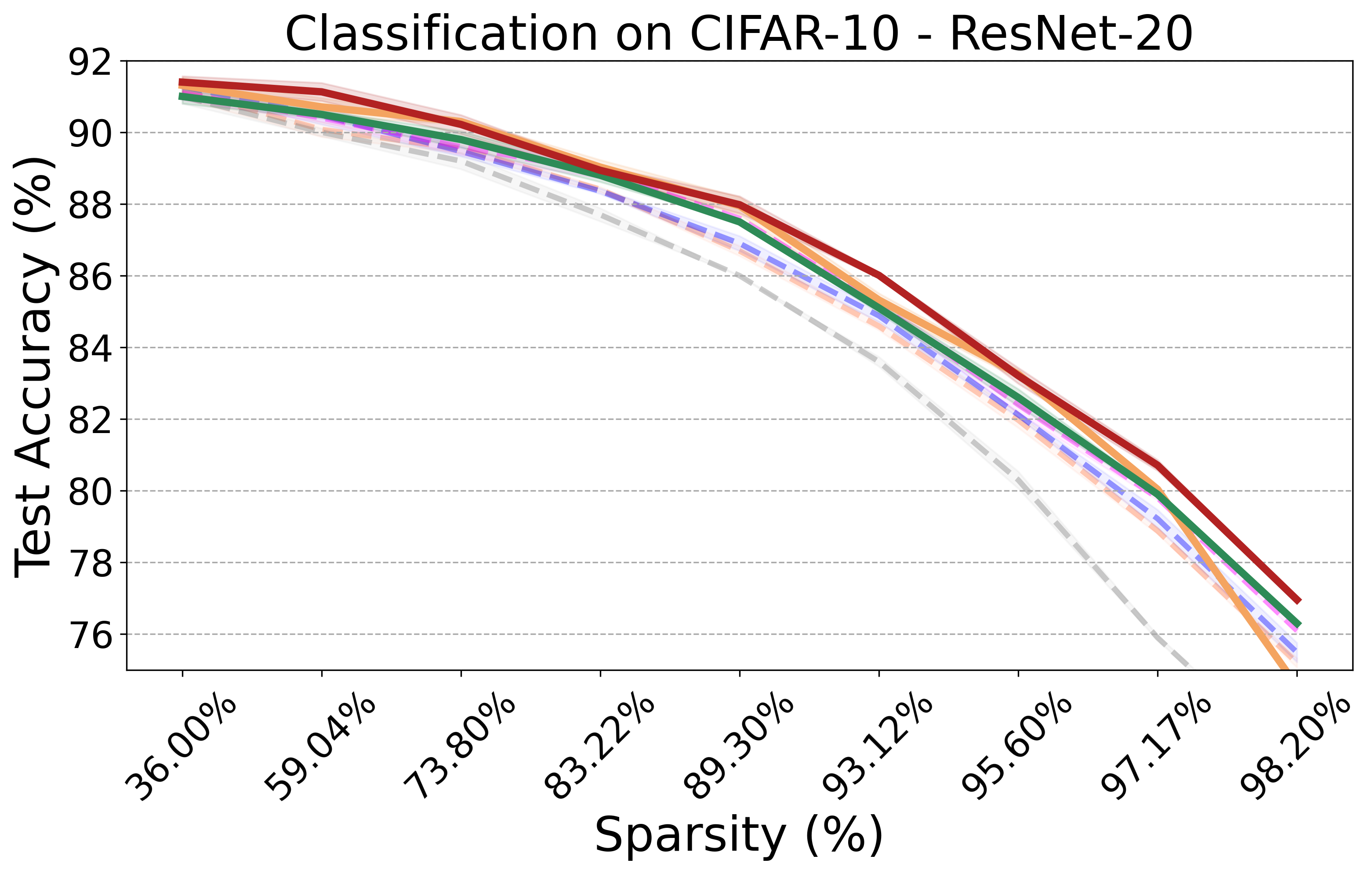
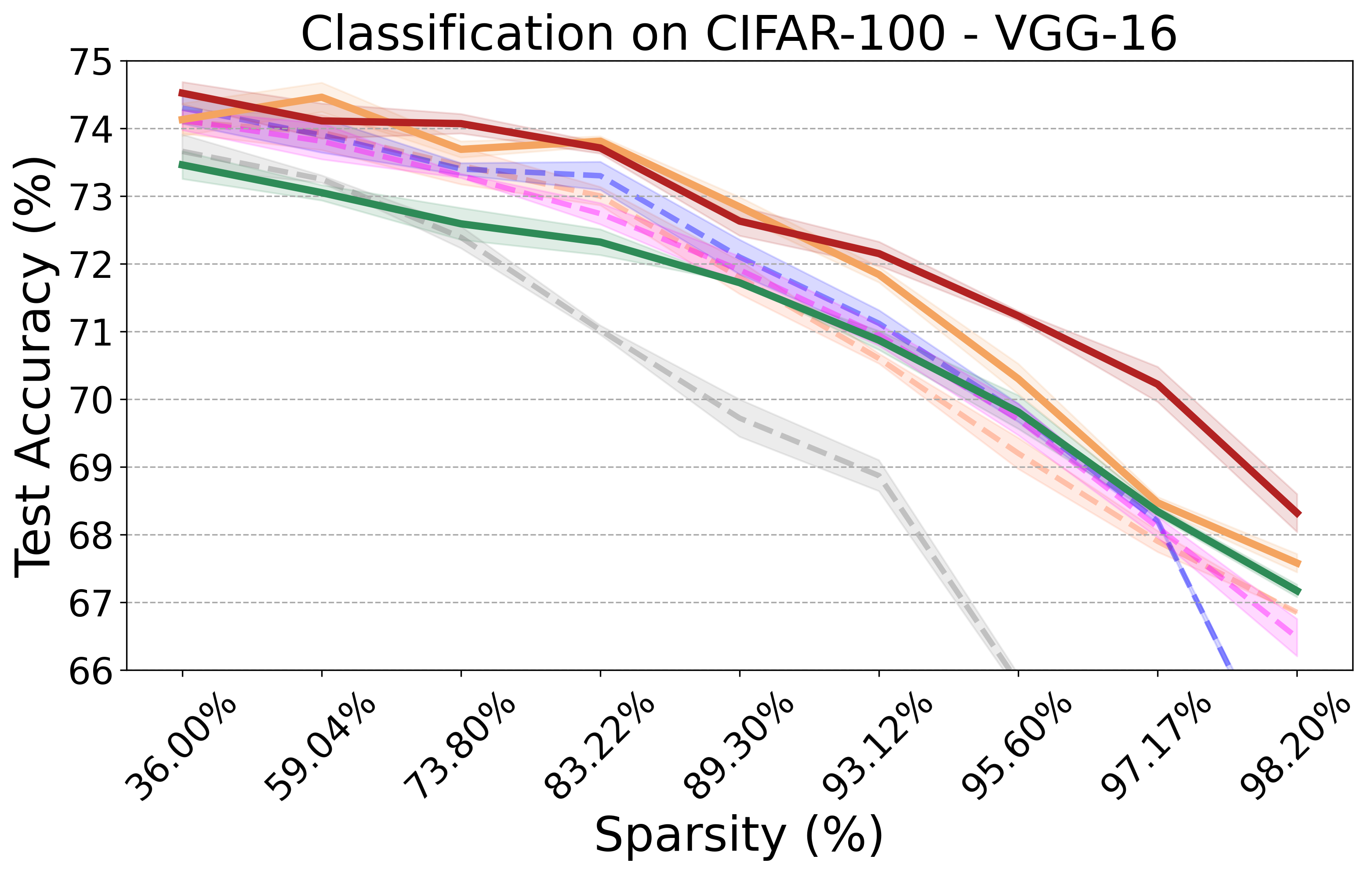
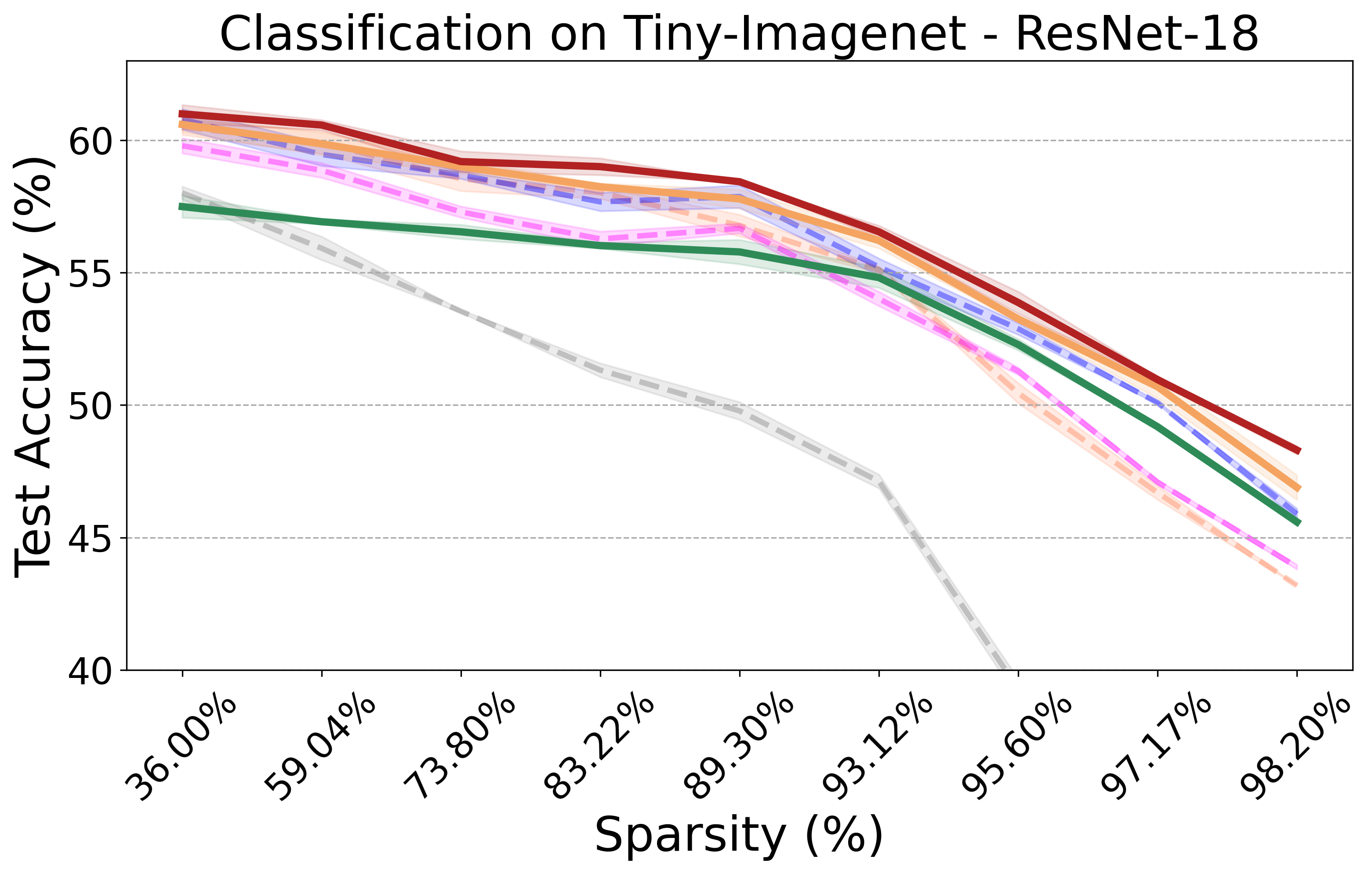
PX demonstrates robust performance across various neural network architectures and tasks, including large pre-trained vision models. It maintains the transferability and effectiveness of pruned networks. The algorithm's theoretical rigor and practical efficiency make it a versatile tool for modern neural network pruning.

@inproceedings{iurada2024finding,
author = {Iurada, Leonardo and Ciccone, Marco and Tommasi, Tatiana},
title = {Finding Lottery Tickets in Vision Models via Data-driven Spectral Foresight Pruning},
booktitle = {CVPR},
year = {2024},
}